
リコー 日本語の精度が高い130億パラメータの大規模言語モデル(LLM)を開発、顧客の業種・業務に合わせたカスタムLLMを2024年春から提供開始
株式会社リコーは、日本企業の業務での活用を目的に、企業ごとのカスタマイズを容易に行える130億パラメータの大規模言語モデル(LLM)を開発した。日本語と英語での学習においてその学習データの比率を工夫することで、日本語としての文法や回答が正確で日本語精度の高い、日本企業が持つ情報資産の活用に適したモデルを実現した。ベンチマークツールを用いた性能検証の結果、日本語で利用できる130億パラメータを持つ日本語LLMにおいて、2024年1月4日現在で最も優れた結果も確認している。
現在、労働人口減少や高齢化を背景に、AIを活用した生産性向上や付加価値の高い働き方が企業成長の課題となっており、その課題解決の手段として、多くの企業がAIの業務活用に注目している。しかし、AIを実際の業務に適用するためには、企業固有の用語や言い回しなどを含む大量のテキストデータをLLMに学習させ、その企業独自のAIモデル(カスタムLLM)を作成する必要があり、課題も抱えている。その上でリコーが開発したLLMでは、米Meta Platforms社が提供する「LLM Llama2-13B」をベースに、日本語と英語のオープンコーパスを追加学習させて開発したものになっている。
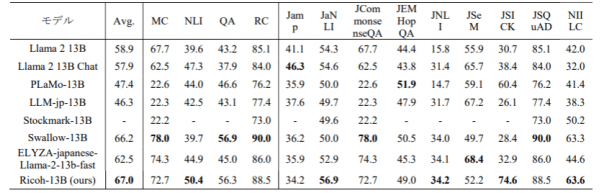
①学習に利用するコーパスの選定、②誤記や重複の修正などのデータクレンジング、③学習データの順序や割合を最適化するカリキュラム学習など、リコー独自の学習上の工夫が組み込まれていることが特徴になっている。学習の結果、特にNLI(自然言語推論能力)において高性能な作りになっている。日本語LLMの性能評価で広く使われている日本語ベンチマークツール(llm-jp-eval)を用いた他LLMモデルとの性能比較では、評価スコアの平均値が最も高く、優れた性能を確認した。
学習能力が高い同LLMに企業独自の情報や知識を取り入れることで、顧客ごとの業種・業務に合わせた高精度なAIモデル(カスタムLLM)を、短期間で容易に構築することが可能になる。カスタムLLMを顧客の業務で活用し、業務文書の要約や質問応答の作業をAIに置き換えることで、業務のワークフローを最適化し、業務効率化を実現することができる。
2024年春より、同カスタムLLMをクラウド環境で提供することを予定している。日本国内の顧客より提供を開始し、今後海外の顧客への提供も目指している。
リコーは、顧客に寄り添い、業種業務に合わせて利用できるAIサービスの提供により、 顧客が取り組むオフィス/現場のデジタルトランスフォーメーション(DX)を支援する。